Anschliessend klicken Sie bitte hier, um die Seite neu zu laden.
Datenanalyse
Titelvarianten: Datenauswertung, Data evaluation, Analysis
Dieses Unterkapitel ist nicht in jedem empirischen Paper vorhanden. Wenn die Analyse relativ einfach ist und keine besonders zu dokumentierenden Methoden verwendet wurden (z.B. einfache Erfassung und Mittelwertbildung von Reaktionszeiten pro Bedingung), kann dies in den Abschnitten «Apparate» oder «Prozedur» oder auch im Resultateteil untergebracht werden.
Ein separates Unterkapitel zur Datenerfassung und/oder Datenauswertung ist z.B. empfehlenswert, wenn
- die erfassten Rohdaten sehr umfangreich sind und mittels spezieller Verfahren vor der inferenzstatistischen Analyse reduziert werden müssen, z.B. bei psychophysischen Experimenten wie EEG, Eye Tracking, fMRI, Codierung von Verhaltensbeobachtungsdaten und ähnlich.
- spezielle, weniger gebräuchliche statistische Methoden verwendet wurden.
- aus den Rohdaten spezielle Messgrössen (Indices) abgeleitet werden, welche konzeptuell genauer erläutert werden müssen.
- eigene Datenbearbeitungsprozeduren programmiert wurden.
- weniger bekannte Algorithmen zur Erstellung der graphischen Darstellungen verwendet wurden.
Das folgende Beispiel stammt aus dem gleichen Artikel wie bereits hier verwendet.
Datenanalyse
Im Experiment wurden
die aufeinanderfolgenden Bilder in randomisiert ausgewählten Grössen jeweils unmittelbar
nacheinander angezeigt, d.h. ohne Leerbild oder ähnlich dazwischen. Daher wurden die
Sakkaden aus der Analyse entfernt, die gemacht wurden, um "in den Bildbereich
hineinzuspringen", wenn ein kleineres Bild auf ein grösseres folgte.
Für die
deskriptive Analyse der Verteilung der Sakkadenamplituden wurden alle Sakkaden aller Vpn
gepoolt, separat für die vier verschiedenen Bildgrössen. Auf der Basis dieser Daten
berechneten wir die deskriptiven Kennwerte wie Mittelwert, Median, Modus usw. Zudem
haben wir eine Histogrammanalyse vorgenommen, um die Verteilung der Sakkadenamplituden
zu illustrieren. Die Histogrammberechnungen wurden mit einer Balkenbreite von 0,5 Grad
vorgenommen.
Für die Inferenzstatistik analysierten wir drei Messgrössen: Da
die Sakkadenamplituden nicht normalverteilt sind, berechneten wir zuerst die den Median
pro Vpn und Bildgrösse über alle Bilder. Als zweites bestimmten wir die Mittelwerte, um
unsere Resultate mit denen der Metaanalyse vergleichen zu können. Drittens haben wir die
Sakkadenamplitude relativ zur Bildgrösse berechnet. Dazu haben wir jeden Amplitudenwert
A in Prozent der maximalen Bildausdehnung
(extent) ausgedrückt, nach der Formel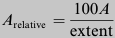 .
.
Danach haben wir wie für die absolute Amplitude die Medianwerte pro Vpn und
Bildgrösse über alle Bilder berechnet.
Für die Signifikanzprüfung verwendeten
wir die GLM-Statistik für abhängige Daten (general linear model, siehe McCullagh
& Nedler, 1989), wie sie in SPSS 12.0.1 implementiert ist (SPSS Inc., Chicago,
IL). Alle Daten wurden vor der Inferenzstatistik mittels Kolmogorov-Smirnov-Test auf
Normalverteilung geprüft; das Kriterium wurde für alle Daten erfüllt. Abweichungen von
der Sphärizitätsannahme (geprüft mittels Mauchly's Test of Sphericity) wurden wenn nötig
korrigiert, indem die Freiheitsgrade nach der Methode von Huynh-Feldt angepasst wurden.
Als Post-hoc-Tests wurden mehrfache Paarvergleiche für abhängige Messdaten berechnet,
wie sie in SPSS implementiert sind.
Übersetzt und modifiziert nach:
von Wartburg,
R., Wurtz, P., Pflugshaupt, T., Nyffeler, T., Lüthi, M. & Müri, R.M. (2007).
Size matters: Saccades during scene perception. Perception,
36, 355-365.